Building Cheap Markerless Full Body Tracking from Scratch
I used to use Tundra trackers for full body tracking in VR. They worked fine until 2.4GHz interference started causing random tracking loss, which got old fast. I switched to SlimeVR thinking that would fix it, and it did, but now I was wearing eight trackers on my body and dealing with constant yaw drift which was frustrating.
I decided that I had to make something myself. My first idea was to recreate constellation tracking, IR leds on your body with multiple camera to triangulate their locations. I looked into it for a while but the math was rough, and working with low resolution cameras and small trackers made it feel pretty infeasible. Additionally, I already knew multiple people attempting to solve this same challenge.
That’s when I started looking into depth sensors. A Kinect V2 can see the full shape of your body in every frame without any markers or trackers. I wanted to see if I could train a machine learning system to estimate accurate joint locations from that.
The idea
Point multiple depth sensors at a person, get their full body pose in real time. No markers, no suit, no expensive hardware. Cheap enough that anyone with a secondhand Kinect can run it.
The tricky part is that real labeled training data for this basically doesn’t exist. My solution was to generate it myself. Render thousands of animated characters in randomized virtual rooms with BlenderProc, add realistic Kinect-style depth noise, and use the ground-truth bone positions from the animations as labels.
Phase 1: Going 3D Too Early
My first instinct was to work directly in 3D. I built a pipeline that reprojects depth pixels into world space, merges point clouds from multiple cameras, and feeds the result into a volumetric neural network. I tried two architectures: V2V-PoseNet, which works over 88³ voxel grids, and PointNet, which operates directly on point clouds. Both are real approaches used in research. Neither worked for me.
The issue wasn’t the models — it was the data pipeline. Getting clean, consistent voxel grids from noisy depth images is hard. Small errors in calibration, depth noise, and denoising stacked up into training data that was too messy for anything to learn from. I spent weeks on the preprocessing and never got past “the loss is going down but the predictions are garbage.” The models ended up just learning to predict a basic standing pose no matter what — it looked fine on average but the moment someone raised a leg or bent their knee, the predictions wouldn’t move at all. It had just memorized the most common pose in the training data as a safe default.
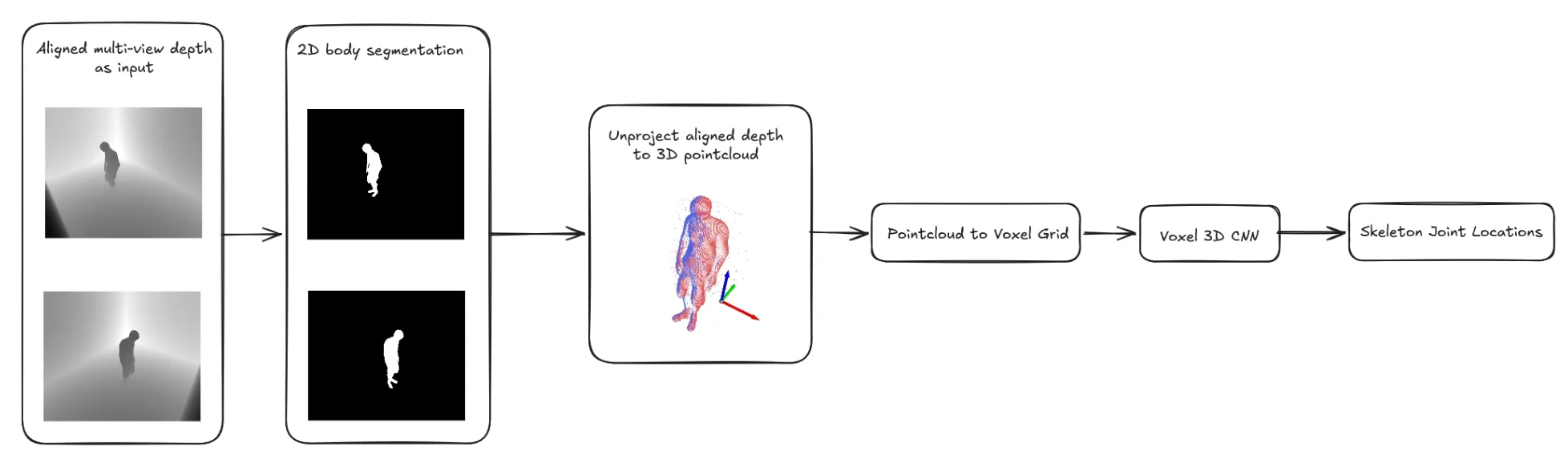
Initial pipeline concept using V2V-PoseNet with volumetric voxel grids
Phase 2: Finding a Better Approach
I came across the RefiNet paper while reading around. The idea is: don’t try to estimate 3D pose from scratch. Use a standard 2D pose estimator to get a rough starting point, then refine those predictions using depth maps.
This works because 2D pose estimation is basically a solved problem: YOLO is fast, accurate, and generalizes well. The depth camera just needs to nudge the predictions into the right place, not figure everything out on its own. Much easier.
I tried it on my synthetic data and it was immediately more promising than anything I’d gotten from the volumetric approach.
Phase 3: Building It
Coarse detection is a fine-tuned yolo26-small pose model trained on the COCO-wholebody dataset. It gives rough 2D joint positions.
RefiNet Module A is a small CNN that takes a small depth patch around each joint and outputs a correction offset. Training is simple: add noise to ground-truth joint positions from the generated dataset from earlier to simulate YOLO’s errors and supervise the correction.
RefiNet Module B takes the refined 2D joints and lifts them to 3D using depth unprojection and a learned skeleton refinement step.
Now it’s actually working, not perfectly but it’s genuinely detecting and refining poses on real Kinect data, which is more than I could say for anything in my initial attempts.
Early demo of the RefiNet pipeline
What’s Next?
The pipeline is the hard part but it’s not the whole thing. Here’s what coming next:
A real GUI. Right now it’s all Python scripts and OpenCV windows. I’m planning to learn C#, .NET, and Avalonia to build a proper desktop app. Something you could actually hand to someone who doesn’t want to touch a terminal.
Multi-sensor support. One depth camera has blind spots. I want to support multiple Kinects with automatic spatial alignment and time sync, fusing views from different angles into one skeleton.
Smoothing. Raw per-frame pose estimates are jittery. Some filtering should clean that up a lot.
The end goal is full body tracking for VR, and maybe motion capture, using hardware that costs under $60 on eBay.